11 minutes
A Practical Guide of GNU awk With Examples
Would you like a powerful, mature, and versatile tool to parse whatever column-shaped content you want very quickly, like a dataset? The CLI tool awk can help you in that regard.
First, to be sure you have GNU awk installed on your computer, you can run in your terminal awk --version. If you don’t have GNU awk (but BSD for example), I would recommend you to install its GNU counterpart. You’ll have access to many more options that way.
This article is a summary of two videos I’ve made with love. They are more detailed and they have some exercises to help you remember everything:
The second part:
To please the Mighty Youtube Algorithm, don’t hesitate to like my videos, subscribe to my channel, send me some love letters, and pray for my soul.
I would also recommend you to:
- Download these files. The examples of this article are based on them.
- Fire up your beautiful shell.
- Play with the examples you’ll see in this article.
I’m sorry to be the one telling you that but you won’t learn much if you only read (or watch a video) passively.
If you want to dig deeper, the awk manual can be summoned with the usual man awk in your shell.
Enough mumbling! Let’s begin our awk adventure.
Basics
Two things are called “awk”: the CLI itself and the programming languages it uses. The CLI can do two basic things:
- Split the input file(s) in sequence of records.
- Break down each record in sequence of fields.
By default, a record is a line, and the fields of a record are strings separated with whitespaces or newline characters. These defaults can be changed as we’ll see below.
The awk programming language is a sequence of patterns with corresponding actions. The actions are executed on the input of the CLI if the records match the patterns. Said differently, the structure of a simple awk command looks like this:
awk '<pattern> { action }'
You can have only one pattern or only one action at a minimum. You can have multiple patterns with multiple actions, too.
Concerning types, there are only two of them in the awk programming language:
- Strings (surrounded with double quotes
") - Numbers.
This might look quite abstract so let’s look at examples from now on.
The Print Action
The print action allow you to… print records. For example:
awk '{ print }' lsblk
Here, lsblk is a file we give to awk as input. You’ll get this output:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 465.8G 0 disk
sda1 8:1 0 200M 0 part /boot
sda2 8:2 0 16G 0 part [SWAP]
sda3 8:3 0 60G 0 part /
sda4 8:4 0 389.6G 0 part /home
The print action is the default action used if you don’t give any to awk. Note that there is no pattern in the command above.
What if we want to print the first field of each record?
awk '{ print $1 }' lsblk
The output will be:
NAME
sda
sda1
sda2
sda3
sda4
Remember: by default, a record is a line, and a field is a string beginning and ending with a whitespace or a newline character. Here, we ask awk to print the first record of every line.
The records are one-indexed, that’s why the first record is $1 and not $0. It begs the question: what’s $0? The best it to try it:
awk '{ print $0 }' lsblk
You’ll get this output:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 465.8G 0 disk
sda1 8:1 0 200M 0 part /boot
sda2 8:2 0 16G 0 part [SWAP]
sda3 8:3 0 60G 0 part /
sda4 8:4 0 389.6G 0 part /home
What happened here? The symbol $0 represents the entire record. That’s why each record are output.
We can also print more than one field. For example:
awk '{ print $1,$2,"hello" }' lsblk
I let you run this command in your shell to see the result. Using a comma , between what you want to output will automatically add a space in the output itself.
Expressions
Now that we saw the most basic action, let’s look at the expressions of the awk programming language. You can use them both in patterns or actions.
First, let’s add a basic pattern to our awk command:
awk '/sda/ { print $1 }' lsblk
Here’s the output:
sda
sda1
sda2
sda3
sda4
We want here to print the first field of every record. The pattern /sda/ will filter the different records: only the records matching the regular expression sda will be used.
We can also use other basic expression in the pattern. For example, if we only want to print the record when its first field is exactly sda, we can do:
awk '$1 == "sda" { print $1,$2,$5 }' lsblk
Here’s the output:
sda 8:0 0
You can play in your shell with the following examples to grasp the concept. They are not difficult to understand if you have some experience with programming languages using a C-like syntax:
awk '$2 == 4+4 ":0" { print $1,$2,$5 }' lsblk
awk '$2 == 4+4 ":0" && $3 < 2' lsblk
awk '$2 == 4+4 ":0" && $3 < 2 { print $1,$2,$5 }' lsblk
You’ll notice here that a space in the pattern (between 4+4 and :0 for example) represents a concatenation. For example, these two commands are equivalent:
awk '$1 == "sda" { print $1,$2,$5 }' lsblk
awk '$1 == "s" "d" "a" { print $1,$2,$5 }' lsblk
Variables
You can use different variables in the awk programming language. Here are some I find the most useful:
NF-Number ofFieldNR-Number ofRecord
NF or Number of Fields
An example is often better than a long chunk of boring text:
awk '{print $1,$4,NF}' lsblk
Here’s the output:
NAME SIZE 7
sda 465.8G 6
sda1 200M 7
sda2 16G 7
sda3 60G 7
sda4 389.6G 7
As you can see, NF display the total number of fields for each record, even if you output only some of them. Practically, NF can be useful to use in the pattern to filter records by their number of fields:
awk 'NF > 6 {print $1,$4,NF}' lsblk
This will output:
NAME SIZE 7
sda1 200M 7
sda2 16G 7
sda3 60G 7
sda4 389.6G 7
Only the records which have more than 6 fields will be printed.
Another tip: we can use NF as a variable by adding a dollar as prefix. As such, $NF will always be the last field of the output. If you have many fields, it might be useful to use the last one as your starting point. For example, $(NF - 1) will target the field before the last one.
NR or Number of Record
The variable NR can be useful to print the record number. For example:
awk '{print NR,$1,$4}' lsblk
Here’s the output:
1 NAME SIZE
2 sda 465.8G
3 sda1 200M
4 sda2 16G
5 sda3 60G
6 sda4 389.6G
If you want to print only specific records, you can use a pattern:
awk 'NR != 1 { print "My disk",$1,"is",$4 }' lsblk
As a result, the first record is not part of the output:
My disk sda is 465.8G
My disk sda1 is 200M
My disk sda2 is 16G
My disk sda3 is 60G
My disk sda4 is 389.6G
Options
Here are a couple of useful options you can use with the CLI:
Changing the Fields Separator
As we already saw above, the default field separator is a whitespace or a newline. You can change this using the option -F (for field).
It’s useful if you want to manipulate a CSV with commas , as separators:
awk -F "," '{print $2}' product_sold.csv
Here’s a short version of the output:
price
20.00
20.00
20.00
20.00
10.00
20.00
12.12
Changing the Value of a Variable
The option -v can change the value of a variable. By default, the value of the variable NR is 0, but you can set it to 10 for example:
awk -v NR=10 '{ print NR,$1 }' lsblk
Here’s the output:
11 NAME
12 sda
13 sda1
14 sda2
15 sda3
16 sda4
You can also create a variable you can use in the pattern or the action:
awk -v "my_var=10" '{ print NR,$1,my_var }' lsblk
Here’s the output:
1 NAME 10
2 sda 10
3 sda1 10
4 sda2 10
5 sda3 10
6 sda4 10
This is very useful to pass to your awk program some external shell variables. For example, the following won’t work:
MYVAR="sda"
awk '$1 ~ $MYVAR {print $1,$4}' lsblk
Why it doesn’t work? The variable $MYVAR is not expanded by the shell in that case. And it’s better that way; otherwise whatever is in the variable would be executed. It could lead to some sort of… awk injection, I guess?
Instead, we can pass the shell variable in our awk program using -v:
MYVAR="sda"
awk -v var="$MYVAR" '$1 ~ var {print $1,$4}' lsblk
This last example will work. The expression ~ means that the first record represented by the symbol $1 needs to match the regular expression of the value of var (that is, sda). We can’t use the notation /var/ with variables to match a regular expression.
Another solution: we can declare our variable just before the file argument:
MYVAR="sda"
awk '$1 ~ var {print $1,$4}' var="$MYVAR" lsblk
With this notation, you can change the value of the variable for each file, by always assigning the variable before the filename. For example:
MYVAR="sda"
awk '$1 ~ var {print $1,$4}' var="$MYVAR" lsblk var="another-pattern" another_file
Writing an awk Program in a File
If you’re awk program begins to be too complicated to write in the shell, you can use the option -f to write it in a file. For example:
echo '{print NR,$1,$4}' > my_awk_program
awk -f my_awk_program lsblk
Special Patterns: BEGIN and END
There are two very useful special patterns you can use in an awk:
BEGIN - Run actions before processing the input.
END - Run actions after processing the input.
You can use multiple BEGIN and END patterns. In that case, the actions associated with the patterns will be executed in order.
The Special Pattern BEGIN
As always, let’s try to uncover the mystery of BEGIN with an example. Here’s our starting point:
awk '{ print $1,$4 }' lsblk
The output:
NAME SIZE
sda 465.8G
sda1 200M
sda2 16G
sda3 60G
sda4 389.6G
What if we want to replace the headers NAME and SIZE with Disk and Size respectively, and adding a new line between the headers and the results?
The pattern BEGIN comes in handy:
awk 'BEGIN {print "Disk","Size","\n"}
NR != 1 { print $1,$4 }' lsblk
What happens here?
- We have two patterns, each of them linked to one action each.
- The first pattern
BEGINexecutes its actionprint "Disk","Size","\n"before processing the input. This action output the headers we want. - The second pattern
NR != 1executes its actionprint $1,$4only if the record is not the first one.
As a result, we don’t output the headers from the input. Here’s the output:
Disk Size
sda 465.8G
sda1 200M
sda2 16G
sda3 60G
sda4 389.6G
The Special Pattern END
The pattern END executes some options after processing the input.
For example, if we want to change the header with BEGIN and count the number of partitions from the file “lsblk”, we can do that:
awk 'BEGIN { print "Disk","Size","\n"; TP=0 }
NR != 1 { print $1,$4 }
/sda[0-9]/ { TP=TP+1 }
END {print"";print "TOTAL PARTITIONS:",TP}' lsblk
Let’s try to understand this awk program:
- We have 4 patterns. Each of them have an action.
- The first action contains a semi-colon
;. It allows us to execute two different expressions in the same action. - The first action print our headers and initialize a variable
TP. - The pattern
NR != 1filter the first record. Every 1st and 4th field of the other records are printed. - The pattern
/sda[0-9]/filter every record which doesn’t match the regex. The action increments the variable TP. - The pattern
ENDwill make sure to execute its action after processing the input. First, it prints an empty string (the equivalent of printing a newline) and, in another expression, it prints a string with the value of the variableTP.
We don’t need to initialize the variable TP here; by default, every variable have the value 0. I find it clearer that way, however.
The pattern / action pairs in the command itself are separated with newlines for readability purposes, but we can separate them with whitespaces too.
Computations From a CSV
We can now compute useful information from a CSV, for example product_sold.csv.
What about counting every product sold for 20 euro?
awk -F "," 'NR != 1 && $2 == 20 {product = product + 1}
END {print product,"products costing 20 euro have been sold"}' product_sold.csv
We could also compute the total of sales as follows:
awk -F "," 'NR != 1 {product = product + $2}
END {print "Total of sales is",product}' product_sold.csv
Useful, isn’t it?
In a Nutshell: a Mindmap of awk
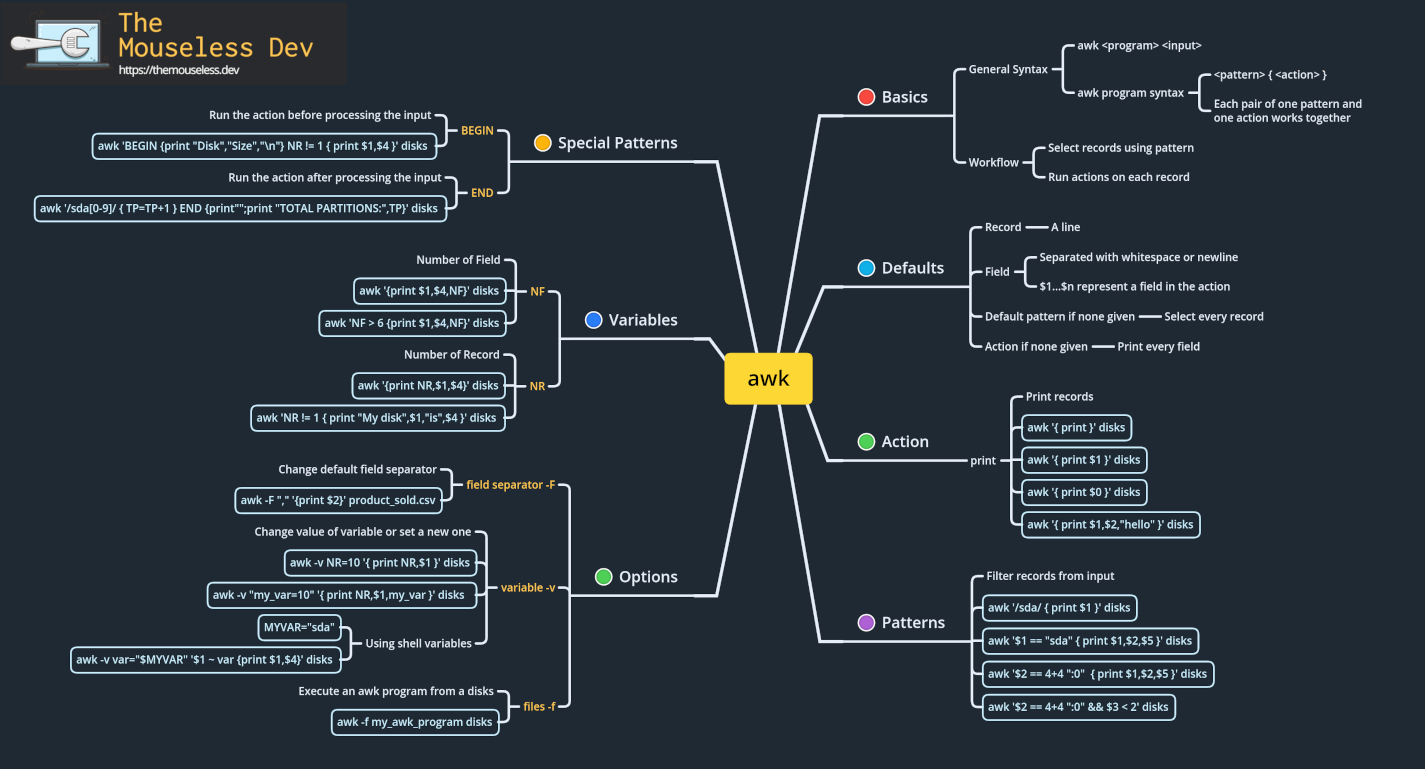
2199 Words
2021-06-25 02:00 +0200